Introducing: Pomsky (formerly Rulex)
Posted on July 4, 2022 by Ludwig Stecher ‐ 7 min read
This year in February, I started a new project, which I named Rulex: A language that is transpiled to regular expressions. A month later, I released the first version of Rulex.
A lot has happened since then, so I wanted to give an update. First, the summary:
Rulex got noticed: It trended on Hacker News and now has over 700 stars on GitHub 🚀
I published my first two security advisories for Rulex on GitHub
I was forced to rename Rulex to Pomsky, because a lawyer claimed that my project violates a registered trademark
Pomsky now has a website with a feature-rich online playground
Pomsky is still in an alpha stage, but it has seen many new features, improvements and bugfixes since its first release.
If you’re using Pomsky, or want to use it, I’d like to hear from you!
What is Pomsky all about?
Regular expressions are a very widespread language; it has implementations in just about every programming language. They’re also very powerful and can come in handy in a variety of situations. Yet, many people dread writing them. Furthermore, decyphering a regex beyond a certain length and complexity is very difficult due to its dense and ambiguous syntax.
Pomsky attempts to solve all the issues that regexes suffer from. Writing Pomsky expressions should be fun and not turn into a maintenance burden. I’ll explain how Pomsky achieves that, but note that Pomsky is not a regex engine. Pomsky is just an alternative syntax that you can use with your regex engine of choice. This has the advantage that Pomsky can be used with all the existing programming languages and APIs that use regexes.
Free-spacing mode
If you want to see what Pomsky looks like, I encourage you to check out the examples on the home page.
The biggest problem with regular expressions is that you have to write everything in a single line without any white space. However, some regex engines have a free-spacing mode, enabled with (?x). In free-spacing mode, spaces and line breaks are ignored, and you can add comments. This is really helpful to make regexes more readable.
Pomsky goes one step further: In Pomsky, free-spacing is the default, and it’s supported for all regex engines, even JavaScript.
No backslash escapes
In theory, the syntax of regexes is quite simple. However, there is one thing that regularly trips people up: There’s a myriad of characters that need to be escaped, and forgetting to escape a character leads to subtle bugs. That’s why Pomsky doesn’t have character escapes. Instead, strings are written in quotes, and you can decide if you prefer double or single quotes.
Compatibility and Unicode support
Even though regex engines such as Java, PCRE or EcmaScript use a similar syntax, there are enough differences that writing portable regexes is difficult. If you want to use the same regex in different engines, you can’t use any of the more advanced features, such as named backreferences or lookbehind, because they either aren’t universally supported, or their behavior or syntax differs slightly between engines.
Pomsky can’t solve this problem entirely. For example, when a regex engine doesn’t support lookbehind, there’s nothing we can do about it. However, Pomsky is able to polyfill some features, so they can be used in regex engines where they aren’t natively supported. For example, Pomsky polyfills named backreferences and proper Unicode support in JavaScript. When using an unsupported feature that Pomsky can’t polyfill, it will show an error message, so you don’t waste time trying it out.
A modern, reimagined syntax
Over the years, a lot of features have been added to regular expressions since they were invented in 1951. However, syntax has been limited by the characters that hold a special meaning in regexes: .+*?^$()[]{}|\. So it’s no surprise that many syntax constructs start with a backslash or with (?. For example, in PCRE, named backreferences use the syntax \k<name>, and comments look like (?# comment).
Pomsky’s syntax is designed with newer features in mind. Furthermore, Pomsky prefers keywords over sigils except for the most commonly used constructs. This makes the syntax much easier to read.
Variables
In Pomsky, you can assign part of an expression to a variable and re-use it as often as you want. This can make more complex expressions much simpler. You can follow the best practice “don’t repeat yourself” (DRY), and document your code in the process by using descriptive variable names.
There is just one limitation: Variables can’t recursively reference themselves. That would cause an infinite loop, since variables are inlined by Pomsky, therefore it is forbidden.
Pomsky’s growth in popularity
After Rulex was posted on Hacker News, it got 200 new stars on GitHub on a single day. Since then, there’s been steady growth, and now it has over 700 stars.
This was really useful for me, because I received hundreds of comments on Reddit and Hacker News by people criticizing, praising and showing alternatives for Rulex. I couldn’t respond to all of them, but reading them gave me a better idea of what people want. It was very encouraging to see other people defending my project against critics. I was also positively surprised that the discussion was quite civil and productive 🙂
My first security advisories
A consequence of the growing popularity was that people started trying out Rulex, and someone even set up fuzzing for it. In case you’re unfamiliar with the concept: A fuzzer is a test harness that tests a program by feeding it with random input, and then systematically altering the input to explore different code paths.
It didn’t take long before the fuzzer found a panic, which is a (usually unrecoverable) error in Rust. After a bit more time, it found another panic and a stack overflow.
After the issues were fixed and the fuzzer had run for hours without bringing up any more panics, I published a patch and disclosed two security advisories a few days later. These have “low severity”, because there’s little chance that they could be exploited. An exploit would have required that a web service accepted and parsed untrusted rulex expressions, which is strongly discouraged by the way!
The good thing is that we are now much more confident in the correctness of the parser. After this incident, the integration test suite has also been improved and extended.
I want to thank Evan Richter for setting up the fuzzer, disclosing the panics to me, and guiding me through the security advisory process.
Renaming Rulex

As announced in my previous post, I had to rename Rulex to Pomsky. Read the announcement to find out the reasons, and why I chose the name “Pomsky”.
If you use the rulex library or the rulex-macro crate, instructions for migrating are in the changelog.
Note that the new AUR package hasn’t been released yet.
The website
Considerable work went into improving the landing page, the documentation and the online playground of Pomsky. When I published the first version, there was an mdbook with documentation. I really like mdbook for its ease of use, but I wanted more customizability, so I rewrote it with Hugo.
The first version of the playground has also since been rewritten in React. It now uses monaco editor, the editor powering VS Code, and supports several IDE features such as intelligent autocompletions and highlighting errors while typing. The playground also supports matching on text now, similar to regexr, although not as advanced.
Where we are now
Although Pomsky is still in an alpha stage, I want to highlight how far we’ve come. In version 0.3.0, two significant new features were introduced: Variables and number ranges. These make Pomsky much more expressive than regular expressions. 0.3.0 also featured relative references. Version 0.4.2 deprecated <%, %>, [codepoint], [cp] and [.] in favor of built-in variables. Several versions also contained bug fixes and improved diagnostics.
These diagnostics are something I’m really proud of:
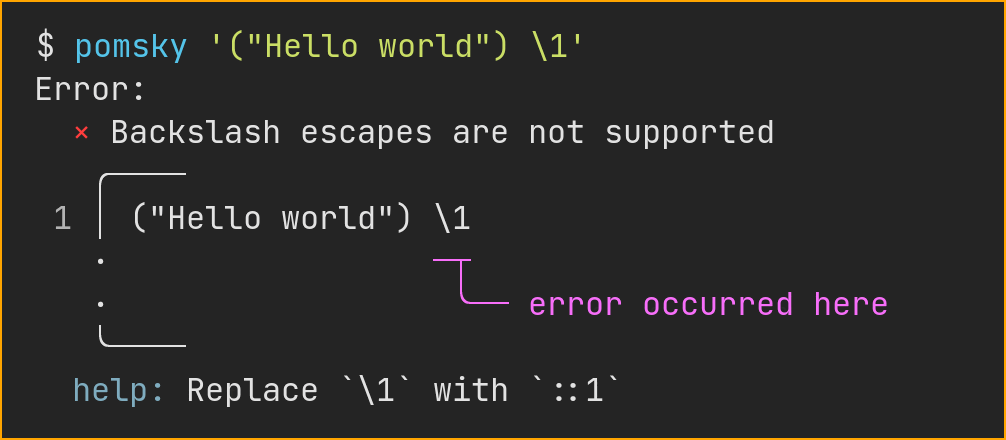
What’s so special about this? Pomsky recogizes a lot of regular expression syntax, so it can show a more useful help message.
But I think we can do better: I’m going to write a tool that converts any regex to a Pomsky expression. This will make it much easier to migrate to Pomsky.
I also have plans to publish a VS Code extension and a babel plugin, to make the development process with Pomsky even smoother. If you have any more suggestions, I’d like to hear them!
Users, where are you?
To inform decisions about the future development of rulex, it would be useful to know how many people are using Pomsky, and how. I would also like to know from people who want to use Pomsky, but can’t for some reason.
However, we currently don’t have that data. Therefore, I’m asking you, if you’re using Pomsky, or would like to, please write a comment in this issue, or send me an email.
Cheers,
Ludwig